To compare the incomparable: json in PostgreSQL vs Mysql vs Mongodb
As such, there's really no “standard” benchmark that will inform you about the best technology to use for your application. Only your requirements, your data, and your infrastructure can tell you what you need to know.
First, a little philosophy. NoSql surrounds and there's no escape (though not very desirable). Leave the questions about root causes beyond the scope of this text, we note only that this trend is not only reflected in the emergence of new NoSql databases, and the development of the old. Another facet of blending of opposites, namely support for storing schema-less data in traditional relational databases. In this gray area at the junction of the relational model of data storage and all the rest lies a dizzying number of possibilities. But, as always, you need to be able to find a balance that is right for your data. It can be difficult, primarily due to the fact that I have little to compare comparable things, for example, the performance of NoSql solutions with the traditional database. In this small note will be offered such an attempt and compares the performance with jsonb in PostgreSQL in Mysql with json and bson in Mongodb.
the
What the hell is going on?
Brief news from the field:
the
-
the
- PostgreSQL 9.4 the new jsonb data type for which support is slightly enhanced in the upcoming PostgreSQL 9.5 the
- Mysql 5.7.7 — a new type of json data
a number of other examples, which will tell you next time. It is remarkable that these data types assume not text, and binary storage of json, which makes working with it much faster. Basic functionality everywhere identical, because it is an obvious requirement to create, select, update, delete. The oldest, almost a cave, man's desire in this situation is to hold a series benchmark's. PostgreSQL & Mysql is selected, because the implementation of the support for json is very similar in both cases (plus they are in the same weight category), but Mongodb NoSql as a veteran of the world. Work, conducted by EnterpriseDB, a little bit in this plan is outdated, but it can take, as a first step to the road of a thousand miles. At the moment, the purpose of this road is not to show who is faster/slower in vitro, and to try to give a neutral assessment and to obtain feedback.
the
Original data and some details
pg_nosql_benchmark from EnterpriseDB assumes a rather obvious way, first is generated a predetermined amount of data of different types with minor fluctuations, which is then recorded in the study database and it happen sample.
Functionality for working with Mysql in it, so it needed to implement the same for PostgreSQL. At this stage there's only one subtlety when we think about indexes — the fact that Mysql is not implemented
indexing json directly, so you have to create a virtual column and index them. In addition, I was confused by the fact that mongodb is part of the generated data size exceeds 4096 bytes, and fits in the mongo shell buffer, i.e., simply discarded. As the hack turned out to satisfy insert's of the js file (which still has to split by chunks a few s since one cannot be more than 2GB). In addition, to avoid the overhead associated with the start of the shell, authentication, etc., is made a corresponding number of "no-op" query, which is then eliminated (although they, in fact, quite small).
With all the changes in the inspections were conducted in the following situations:
the
-
the
- PostgreSQL 9.5 beta1, gin the
- PostgreSQL 9.5 beta1, jsonb_path_ops the
- PostgreSQL 9.5 beta1, jsquery the
- Mysql 5.7.9 the
- Mongodb WiredTiger storage engine 3.2.0 the
- Mongodb MMAPv1 storage engine 3.2.0
Each of them was deployed on a separate m4.xlarge instance with ubuntu 14.04 x64 on-Board with the default settings, the tests were conducted on the number of entries equal to 1000000. For tests with jsquery need to read the readme and remember to set the bison, flex, libpq-dev and even postgresql-server-dev-9.5. The results are saved in a json file that can be visualized using matplotlib (see here).
In addition to this, there were doubts about the settings associated with durability. So I ran a couple other tests for the following cases (in my opinion, part of it is more of a theory, because it is unlikely someone will use these settings in alive):
the
-
the
- Mongodb 3.2.0 journaled (writeConcern j:true) the
- Mongodb 3.2.0 fsync (transaction_sync=(enabled=true,method=fsync)) the
- PostgreSQL 9.5 beta 1, no fsync (fsync=off) the
- Mysql 5.7.9, no fsync (innodb_flush_method=nosync)
the
Images
All graphics are related to the query execution time, represented in seconds, associated with the size — in megabytes. Accordingly, for both cases, the smaller the value, the higher the capacity.
the
Select

the
Insert
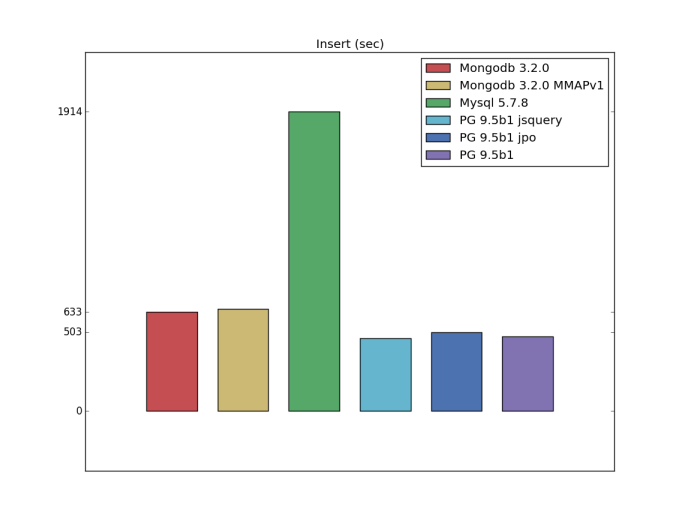
the
Insert (custom configuration)
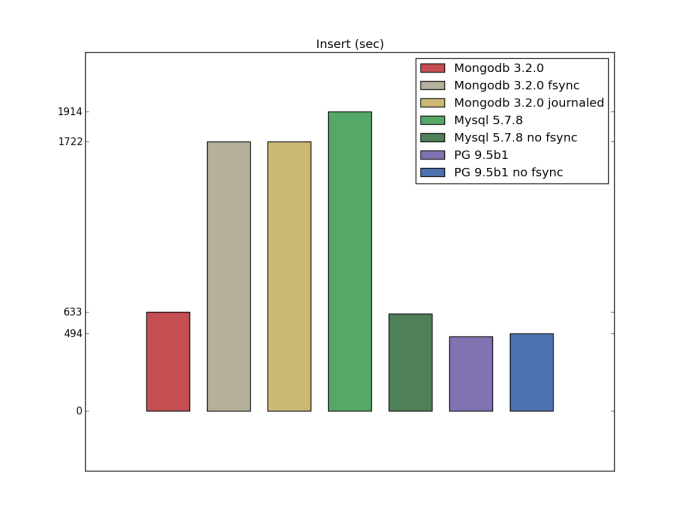
the
Update
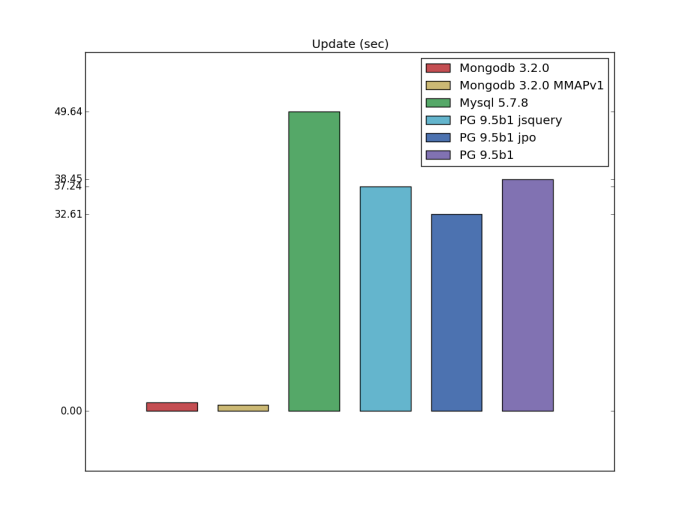
Another change relative to the original code pg_nosql_benchmark was the addition of tests to update. Here is the clear leader was Mongodb, most likely due to the fact that PostgreSQL and Mysql update one value at this moment means overwriting the entire field.
the
Update (custom configuration)
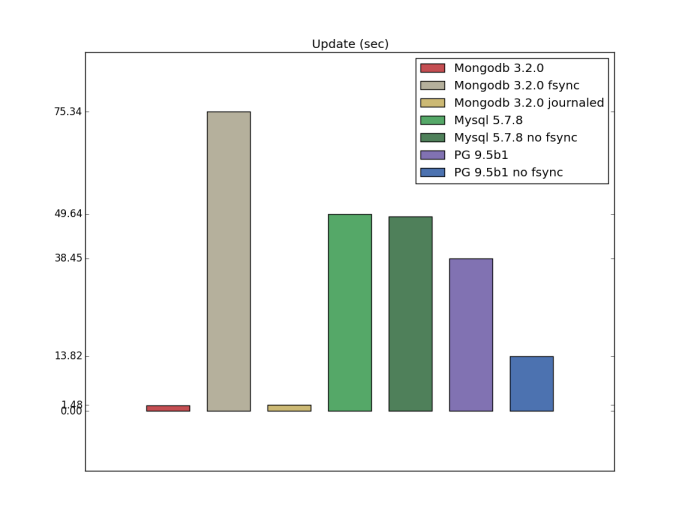
As you can guess from the documentation and watch this reply, writeConcern j:true is the highest possible level of durability for a single mongodb server, and apparently it needs to be equivalent configurations with fsync. I have not tested the durability, but it is interesting that for mongodb update operations with fsync is much slower.
the
Table/index size
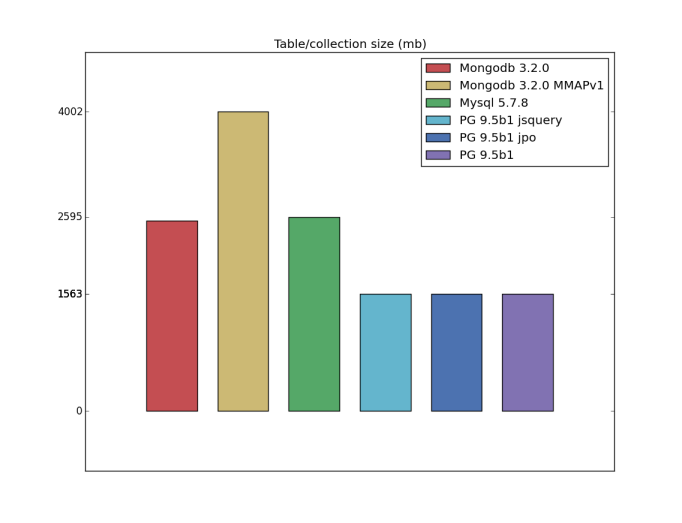
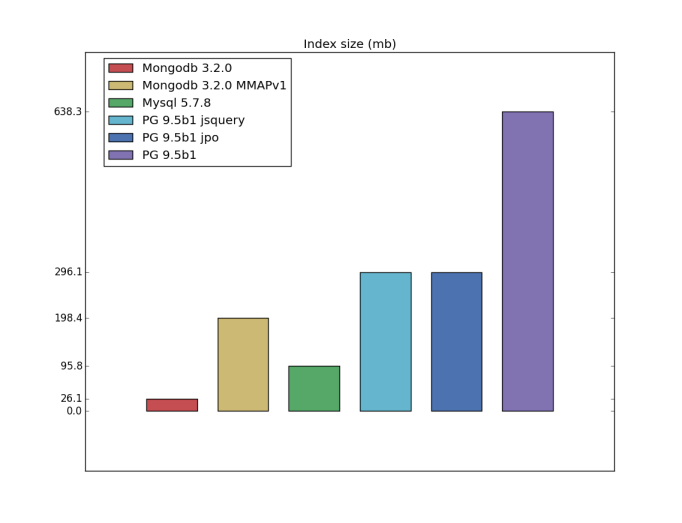
the
I have a bad feeling about this
Performance measurement — too slippery topic, especially in this case. All that is described above, cannot be considered a full and complete benchmark, is only the first step to understand the current situation — something like food for thought. At the moment we are conducting tests using ycsb and, if we're lucky, we compare the performance of cluster configurations. In addition, I will be glad for all constructive suggestions, ideas and corrections (because I could miss something).


Комментарии
Отправить комментарий