How to use artificial intelligence to solve SEO tasks

Search the model must be capable of "self-calibration". That is, it must be able to take their algorithms, their specific weight and compare modeled data with public search engines to identify the most accurate search engine that allows you to simulate any environment.
However, the analysis of thousands of parameters, trying to find the best combination of them is astronomically expensive in terms of computational processing, and also very difficult.
So how, in this case, to create a self-calibrating search model? Turns out the only thing that remains for us is to seek the assistance of... birds. Yes, you heard right, specifically to the birds!
the
optimization using the particle swarm optimization (PSO)
Often it happens that a grandiose problem find the most unexpected solutions. For example, you should pay attention to the optimization using particle swarm, which is a method of artificial intelligence, first mentioned in 1995 and based on the socio-psychological behavioral patterns of the crowd. The technique is actually modeled on the concept of behavior of birds in the flock.
In fact, all algorithms working on rules that we created today, still can't be used to find at least approximate solutions to the most difficult problems for numerical maximization or minimization. However, using such a simple model as a flock of birds, you will immediately be able to answer. We heard dire predictions about how one day artificial intelligence will take over the world. However, in this particular case, he as time becomes our most precious ally.
Scientists engaged in the development and implementation of many projects dedicated to Swarm intelligence. So, in February 1998, a project was launched "Millibot", formerly known as "Cyberscout" — a program that involved marine corps. Cyberscout was, in fact, a Legion of tiny robots that can infiltrate into the building, covering all its territory. The ability of these high-tech babies to communicate and share among themselves information gave the ability to "swarm" of robots to act as a single whole body, making extremely time-consuming to study the whole building in a leisurely walk along the corridor (most of the robots were able to drive no more than a couple of meters).
the
Why it works?
In PSO really cool is that the method makes no assumptions about the problem you are trying to solve. It is a cross between a rules-based algorithm that tries to work out a solution and neural networks artificial intelligence, which aims to explore the issues. Thus, this algorithm is a compromise between exploratory and exploitative behavior.
Not having exploratory nature, this optimization approach, the algorithm, of course, would be what statisticians call a "local maximum" (a solution that seems optimal, but is not really).
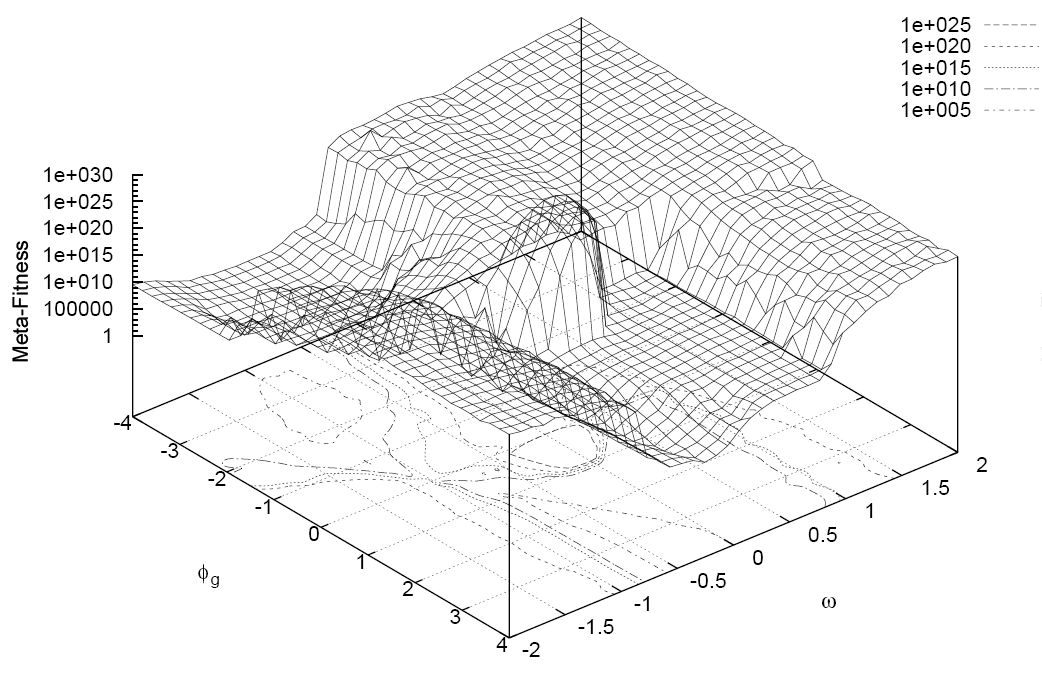
First you start with several "flocks" or guesses. In search models it can be various weights of scoring algorithms. For example, with 7 different inputs, you will begin at least 7 different assumptions about these weights.

The idea of PSO is that each of these assumptions was as far away from the rest. Without going into 7-dimensional calculations, you can use several techniques to make sure your starting points are optimal.
Then you will begin to develop their guesses. In this course you will simulate the behavior of birds in a flock in a situation where there is food. One of the random guesses (flocks) will be closer than others, and each subsequent guess will be adjusted on the basis of General information.
The visualization, shown below, demonstrates this process.
the
Implementation
Fortunately, there are a number of possibilities to implement this method in different programming languages. And the great thing about optimizing using particle swarm optimization is that it can easily be translated into a reality! The technique has minimum settings (is an indicator of a strong algorithm) and a very short list of limitations.
Depending on your problem, the idea and its implementation can be found in the local minimum (not optimal solution). You can easily fix this by introducing the neighborhood topology, which will quickly limit the feedback loop to the finest assumptions.
The main part of your work will consist in the development of "opportunistic function" or a ranking algorithm that you will use to determine the degree of closeness to the target correlation. In our case, with SEO, we will have to correlate data with some predefined object, such as results from Google or any other search engine.

If you have a working scoring system, your PSO algorithm will try to maximize the results through the trillions of potential combinations. The scoring system can be as simple as performing Pearson's correlation between your search model and search results of Internet users. Or it may be as complex as the simultaneous activation of these correlations and the assignment of points to each specific scenario.
the
Correlation to the "black box"
In recent years, many SEO optimizers try to perform a correlation regarding the "black box" Google. These efforts, of course, have the right to life, but they're mostly useless. And here's why.
First, correlation does not always imply the existence of a causal relationship. Especially if the entry points to your black box are not too close to the exit points. Let's look at an example where the entry points are very close to their corresponding exit points — the ice cream transportation business. When it's hot outside, people buy more ice cream. It's easy to see that the entry point (air temperature) is closely tied to the exit point (ice cream).
Unfortunately, the majority of SEO-optimizers do not use statistical proximity between their optimizations (entries) and their corresponding search results (outputs).
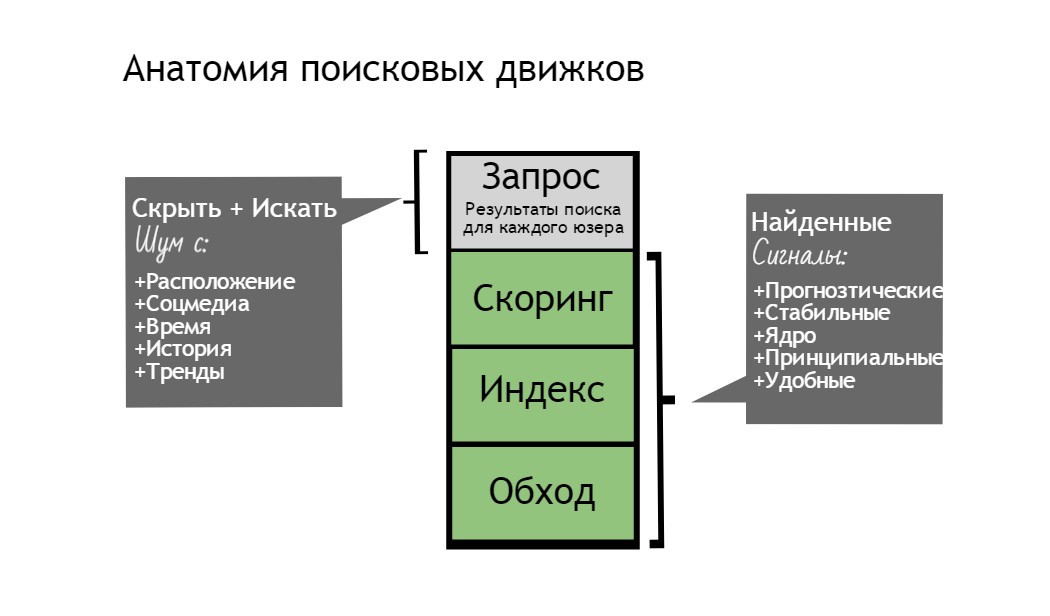
Moreover, their inputs, or optimizations, are before bypass components in the search system. In fact, a typical optimization must go through 4 levels: crawling, indexing, scoring and, ultimately, the level of real-time request. Trying to correlate this way can result in nothing but wasted expectations.
In fact, Google provides a significant noise factor, just as the U.S. government creates a buzz around your network GPS, which civilians do not have the opportunity to obtain the same accurate data as the military. This is called the level of queries in real time. And this layer becomes a serious limiting factor for the tactics SEO-correlations.
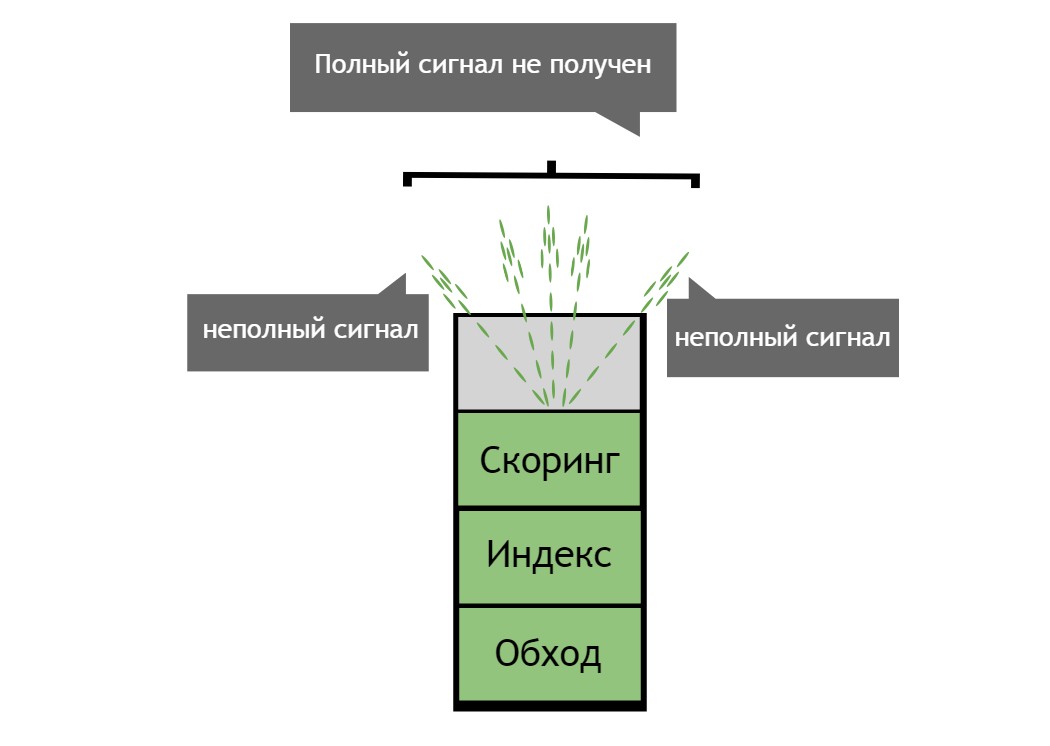
As an example here you can put a garden hose. On the scoring level of the search engine you get a look at what is happening around. Water coming from the garden hose, organized and predictable – so you can change the position of the hose and to predict the corresponding change of flow of water (search results).
In our case, the query layer spray this water (search results) in millions of drops (variations) depending on a user. Most changing algorithms today appear on the request level so that for the same number of users producing a greater number of variations of search results. Hummingbird algorithm from Google is one example. Shifts level queries allow the search engines to generate more trading platforms for their PPC ads.
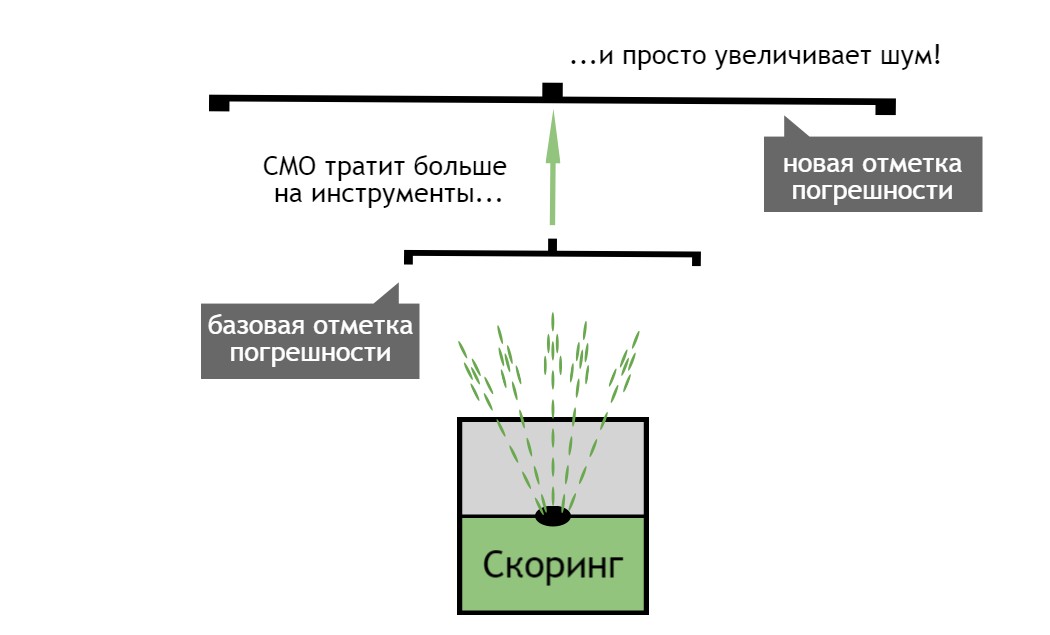
The level of queries is the opinion of users and not on what is happening. Therefore, the correlations derived in this way will be extremely rare to have a causal relationship. And this is assuming that you have one tool to find and model the data. As a rule, however, SEO-optimizers use a variety of input data that will increase noise and decrease the possibility of finding causal relationships.
the
causality SEO
To get correlation to work with the search engine model we can significantly tighten the inputs and outputs. In the search engine model input or variable data must be in a scoring level or above. How to do it? We need to break the black box search system on key components and then to build a model engine from scratch.
To optimize your exits even more difficult due to the horrific noise resulting from layer requests in real-time, which is due to each user, creates millions of variations. As a minimum, we will need to create such entries for our model search system, which will be located before the normal layer with variations of queries. This ensures that at least one of the compared sides stable.
Building a search engine model from scratch, we will display search results coming not from the level of needs, and directly from the scoring layer. This will give us a more stable and precise relationship between the inputs and outputs that we are trying to correlate. And then, thanks to this durable and illustrative relationships between inputs and outputs correlation reflect a causal relationship. Focusing on one input, we get a direct link with the results that we see. Then we will be able to make a classic seo-analysis to determine the optimization option will be beneficial for the existing search engine model.
the
Results
A situation when some simple thing in nature leads to scientific discoveries or technological breakthroughs can not but admire. Having a search engine model that allows us to openly connect scoring inputs with non-personalized search results, we can associate correlation with causality.
Add to that the optimization method of particle swarm, and you have a technological breakthrough – self-calibrating search model.


Комментарии
Отправить комментарий