Clustering web applications on hosting Amazon Web Services
the Theme of high-load applications at all on hearing. Also decided to throw in my 5 cents and to share the experience of creating highload applications on AWS infrastructure.
First, I will be banal and repeat well-known truths. There are 2 ways to scale your application:
1) vertical scaling is the increase in performance for each system component (CPU, RAM, other components);
2) horizontal, when you combine several elements together, and the whole system consists of multiple computing nodes to solve a common task, thereby increasing overall reliability and system availability. And the performance increase is achieved by adding to the system additional nodes.
The first approach is good, but has a significant drawback — the limited capacity of a single compute node — it is impossible infinitely to increase the frequency of processor cores and the bus bandwidth.
So the horizontal scaling is considerably better than its vertical brother, because with a lack of performance, you can add a node (or group of nodes).
Recently, we once again comprehend all the charm of horizontal scaling in practice: build highly reliable social service for fans of American football, maintaining the peak load of 200,000 requests per minute. So I want to tell you about our experience of creating highly scalable system on Amazon Web Services.
Usually, the architecture of the web application looks like the following:
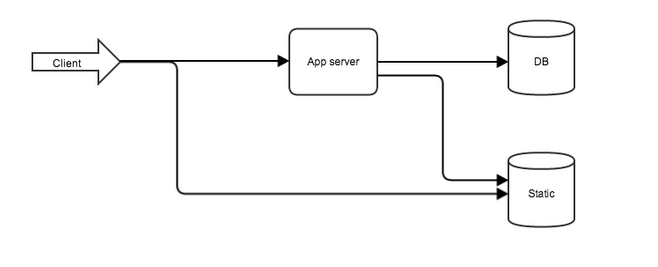
Fig. 1. A typical architecture of a web application
the
Most often, the bottlenecks in the system are the application code and the database, therefore, is to provide for the possibility of parallelization. We used:
the
First thing, spend the maximum optimization of code and database queries and then divide the application into several parts, the nature of the tasks they perform. Individual servers make:
the
Each participant of the system is the individual approach. So choose the server most appropriate for the nature of the tasks parameters.
The app is best suited the server with the largest number of processor cores (to serve a large number of concurrent users). Amazon provides a set of Computer Optimized Instances that best fit these goals.
What is a database? — Numerous disk input / output (record and data reading). Here the best option will be the server with the fastest hard disk (e.g. SSD). And again Amazon it's a pleasure and offers us Storage Optimized Instances, but it will also server line of General Purpose (large or xlarge), because in the future I'm going to scale them.
For static resources do not need any powerful processor or a large amount of memory, then the choice falls on service static resources Amazon Simple Storage Service.
Dividing the application, I led him to the scheme shown in Fig. 1.
The pros of the split:
the
But the app itself is still necessarium, there is no cache server and replication sessions.
For accurate experiments and performance testing of the application we will need one or more machines with a wide channel. User actions will be emulated by the utility Apache Jmeter. It is good because it allows the test data to use real access logs from the server or from the proxy browser and to run a few hundred concurrent threads.
Thus, the experiments showed that the obtained performance is still lacking, and the application server was loaded at 100% (the weak link was the code of the developed application). Thread. The game introduces 2 new elements:
the
As it turned out, the application can not cope with its load, therefore the load should be divided between several servers.
As a load balancer, you can open another server with a wide channel and configure special software (haproxy[], nginx [] DNS[]), but since you are working in the infrastructure of Amazon, we will use an existing service ELB (Elastic Load Balancer). It is very easy to set up and has good performance. The first step is to clone the existing machine with the application for subsequent addition of a pair of machines in blanshirovat. Cloning is performed by means of Amazon AMI. ELB automatically monitors the condition added to the list of cars, this app should implement a simple ping resource that will answer with 200 code to the query, it tells the load balancer.
So, after konfiguriranje load balancer to work with the already two existing servers with the app, configure DNS to work through the load balancer.
This item can be skipped, if the application is not imposed upon the http session, additional work, or if you implement a simple REST service. Otherwise, it is necessary that all applications participating in balancing, have access to the shared storage sessions. Storage sessions run one large instance and configure it ram memcached. Replication sessions are the responsibility of the module to Tomcat: memcached-session-manager [5]
The system now looks as follows (the server is static is omitted to simplify the diagram):
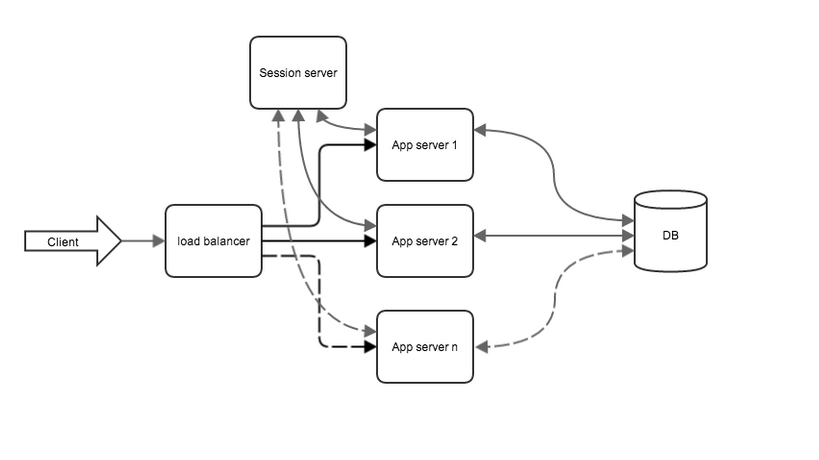
Fig. 2. View of the system after clustering application
The results of clustering applications:
the
With an increasing number of servers c application also increases the load on the database, with which she over time can not handle. It is necessary to reduce the load on the database.
So, again conducted load testing with Apache Jmeter and this time everything depends on the performance of the database. Optimizing the work with the database, use two approaches: caching of queries and database replication for read requests.
The basic idea keshirovaniya is to those data that are requested most often to memorize in the RAM and the repetition of queries the first thing to check, whether the requested data is in the cache and only in case of their absence to make queries to the database, followed by putting the query results into the cache. Caching was deployed an additional server to the configured memcached and sufficient amount of RAM.
The specifics of our application involves to a greater extent data reading than record.
So clusterize DB reading. Here is helping the replication mechanism of the database. Replication in MongoDB consists of the following: database server are divided into masters and slaves, while video record data is allowed only for the master, it is already happening sync data on the slave, and the reading is enabled as the master and the slave.

Fig. 3 Clustering the database for reading
In the result we have achieved the desired: the system handles 200,000 requests per minute.
Article based on information from habrahabr.ru
First, I will be banal and repeat well-known truths. There are 2 ways to scale your application:
1) vertical scaling is the increase in performance for each system component (CPU, RAM, other components);
2) horizontal, when you combine several elements together, and the whole system consists of multiple computing nodes to solve a common task, thereby increasing overall reliability and system availability. And the performance increase is achieved by adding to the system additional nodes.
The first approach is good, but has a significant drawback — the limited capacity of a single compute node — it is impossible infinitely to increase the frequency of processor cores and the bus bandwidth.
So the horizontal scaling is considerably better than its vertical brother, because with a lack of performance, you can add a node (or group of nodes).
Recently, we once again comprehend all the charm of horizontal scaling in practice: build highly reliable social service for fans of American football, maintaining the peak load of 200,000 requests per minute. So I want to tell you about our experience of creating highly scalable system on Amazon Web Services.
Usually, the architecture of the web application looks like the following:
Fig. 1. A typical architecture of a web application
the
-
the
- of the first user meets a web server on his shoulders mandated return static resources and transfer of requests to the application; the
- then the baton is passed to the application, which takes place all business logic and interaction with the database.
Most often, the bottlenecks in the system are the application code and the database, therefore, is to provide for the possibility of parallelization. We used:
the
-
the
- development language and core framework — java 7 and rest jersey the
- application server — tomcat 7 the
- database — MongoDB (NoSQL) the
- system cache — memcached
As it was, or through thorns to high load
Step one: divide and conquer
First thing, spend the maximum optimization of code and database queries and then divide the application into several parts, the nature of the tasks they perform. Individual servers make:
the
-
the
- the application server; the
- the database server; the
- server with static resources.
Each participant of the system is the individual approach. So choose the server most appropriate for the nature of the tasks parameters.
application Server
The app is best suited the server with the largest number of processor cores (to serve a large number of concurrent users). Amazon provides a set of Computer Optimized Instances that best fit these goals.
database Server
What is a database? — Numerous disk input / output (record and data reading). Here the best option will be the server with the fastest hard disk (e.g. SSD). And again Amazon it's a pleasure and offers us Storage Optimized Instances, but it will also server line of General Purpose (large or xlarge), because in the future I'm going to scale them.
Static resources
For static resources do not need any powerful processor or a large amount of memory, then the choice falls on service static resources Amazon Simple Storage Service.
Dividing the application, I led him to the scheme shown in Fig. 1.
The pros of the split:
the
-
the
- each element of the system works on as much as possible adapted to your needs; the
- you can separately test the different elements of the system for weaknesses.
But the app itself is still necessarium, there is no cache server and replication sessions.
Step two: experiments
For accurate experiments and performance testing of the application we will need one or more machines with a wide channel. User actions will be emulated by the utility Apache Jmeter. It is good because it allows the test data to use real access logs from the server or from the proxy browser and to run a few hundred concurrent threads.
Step three: load balancing
Thus, the experiments showed that the obtained performance is still lacking, and the application server was loaded at 100% (the weak link was the code of the developed application). Thread. The game introduces 2 new elements:
the
-
the
- load balancer the
- server sessions
Balansirovka load
As it turned out, the application can not cope with its load, therefore the load should be divided between several servers.
As a load balancer, you can open another server with a wide channel and configure special software (haproxy[], nginx [] DNS[]), but since you are working in the infrastructure of Amazon, we will use an existing service ELB (Elastic Load Balancer). It is very easy to set up and has good performance. The first step is to clone the existing machine with the application for subsequent addition of a pair of machines in blanshirovat. Cloning is performed by means of Amazon AMI. ELB automatically monitors the condition added to the list of cars, this app should implement a simple ping resource that will answer with 200 code to the query, it tells the load balancer.
So, after konfiguriranje load balancer to work with the already two existing servers with the app, configure DNS to work through the load balancer.
Replicating sessions
This item can be skipped, if the application is not imposed upon the http session, additional work, or if you implement a simple REST service. Otherwise, it is necessary that all applications participating in balancing, have access to the shared storage sessions. Storage sessions run one large instance and configure it ram memcached. Replication sessions are the responsibility of the module to Tomcat: memcached-session-manager [5]
The system now looks as follows (the server is static is omitted to simplify the diagram):
Fig. 2. View of the system after clustering application
The results of clustering applications:
the
-
the
- improves reliability of system. Even after the failure of one server application, the load balancer excludes it from distribution, and the system continues to function; the
- to increase performance you just want to add another compute node with the application; the
- adding additional nodes, we can achieve peak performance at 70,000 requests per minute.
With an increasing number of servers c application also increases the load on the database, with which she over time can not handle. It is necessary to reduce the load on the database.
Step 4: optimizing database
So, again conducted load testing with Apache Jmeter and this time everything depends on the performance of the database. Optimizing the work with the database, use two approaches: caching of queries and database replication for read requests.
Caching
The basic idea keshirovaniya is to those data that are requested most often to memorize in the RAM and the repetition of queries the first thing to check, whether the requested data is in the cache and only in case of their absence to make queries to the database, followed by putting the query results into the cache. Caching was deployed an additional server to the configured memcached and sufficient amount of RAM.
Replication, database
The specifics of our application involves to a greater extent data reading than record.
So clusterize DB reading. Here is helping the replication mechanism of the database. Replication in MongoDB consists of the following: database server are divided into masters and slaves, while video record data is allowed only for the master, it is already happening sync data on the slave, and the reading is enabled as the master and the slave.
Fig. 3 Clustering the database for reading
Final: 200K requests per minute
In the result we have achieved the desired: the system handles 200,000 requests per minute.


Комментарии
Отправить комментарий