"4 weddings and a funeral" or linear regression to analyze the open data of Moscow government
Despite the many wonderful materials for the Data Science for example, from Open Science Data, I continue to collect scraps from the feast of reason and continue to share with you their experiences on the development of skills in machine learning and data analysis from scratch.
In recent articles, we looked at a couple of tasks according to the classification in the process of sweat and blood producing their own data, now it's time regression. Because nothing lighting this time at hand was not, I decided to scrape the bottom of the other bottom of the barrel.
I remember in one of the articles I campaigned readers to look towards domestic open data. But since I'm not a young lady of advertising "buttermilk for digestion" or shampoo with horsepower, I couldn't advise anything that is not experienced.
Where to start? Of course with open data of the government of the Russian Federation, there is in fact a whole Ministry there. My acquaintance open data of the government of the Russian Federation, about the same as the illustration to this article. No well not that I wasn't interesting registry Cinema city Novy Urengoy or a list of rolling equipment to the rink in Tula, just for the regression task, they are not very good.
If you dig and think on the website OD the government of the Russian Federation it is possible to find something worthwhile, just not very easily.
Treasury Data I also decided to leave for later.
Perhaps, most of all I liked open data of Moscow government, there I found a couple of potential problems and chose in the end Details about registration of acts of civil status in Moscow by year
What emerged from the implementation of minimum skills in the field of linear regression in summary form to look at GitHuband, of course, looking at kat.

UPD: Added section – "Bonus"
the
As usual, in the beginning of the article will talk about the skills necessary for understanding this article.
You will need:
the
If you are very new in the field of data analysis and machine learning view past articles of the series in order, there is every article written by the "hot pursuit" and you will understand if You should spend time on Data Science.
All of the previously prepared article below.
Well, as promised earlier now article in this series will be completed with content.
Contents:
Part I: "to Marry — not the bast wear" — acquisition and primary data analysis.
Part II: "One man is no man" — Regression for 1 basis
Part IV: "all is Not gold that glitters" — Add signs
Part V: "Cut new Abaya, and to the old try!" — Trend forecast
Bonus — Increases the accuracy, at the expense of another approach to months
So, let's get more to the task. It is our goal to dig up some data set sufficient to demonstrate the basic techniques of linear regression and determine that we will predict.
This time will be brief and I will not deviate from the topic examined only the linear regression (you probably know about the existence of other methods)
the
Unfortunately open data of the government of Moscow is not so vast and boundless as the budget spent on the improvement of the program "My street", but nonetheless something good to find managed.
Dynamics of registration of civil status acts, we should be fine.
It is nearly a hundred entries, divided by months in which there are data on the number of weddings, births, establishment of parenthood, deaths, changes of name, etc.
To solve the problem of regression is fine.
All the code hosted on GitHub
Well then we dissect it right now.
To begin importing the library:
the
Then load the data. The Pandas library allows you to download files from a remote server that in General is just great, provided of course that the portal will not change the algorithm of redirection pages.
(I hope that the download link in the code, will not be covered if it stops working please write in "personal", so I can update)
the
Look at the data:
the
If we want to use information about months, they must be translated into an understandable model format, scikit-learn has its own methods, but for reliability we will make (for not a lot of work) and at the same time remove a couple of useless in our case, the columns ID and junk.
note: in this case, the graph of the Month, I think it would be more appropriate to use one-hot encoding, but because in this case us quality predictions are not much interested, I will leave it as is.
UPD: broke down and added a corrected version in the Bonus
the
Because I'm not sure that table view all opens normally look at the data with the help of pictures.

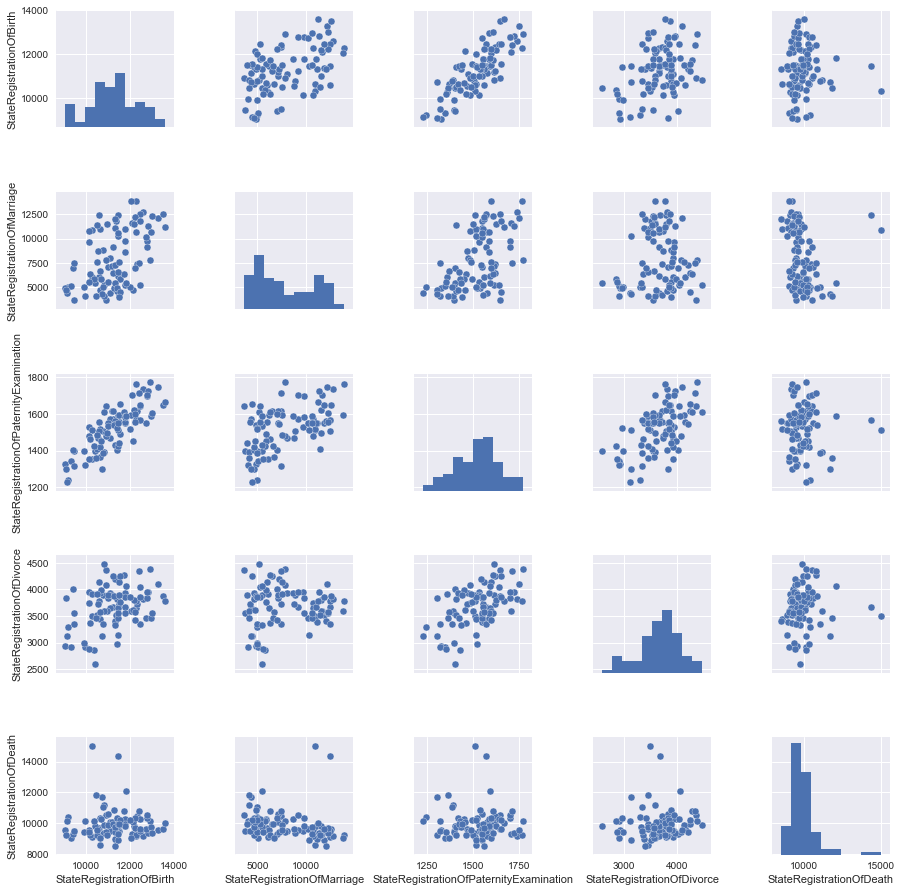
Build a pair of charts, from which it will be clear which columns of our table, linearly independent from each other. However, once all of the data we will not consider, so you have something to add, so first get some data.
A fairly simple way to highlight (delete) a subset of columns in a pandas Dataframe is just to make selection according to the desired columns:
the
Well now you can and schedule to build.
the
A good practice is to feature scaling, not to compare horses with the weight of the stacks of hay and the average atmospheric pressure during the month.
In our case, all data are presented in the same units (number of registered acts), but let's see what will change the scaling.
the
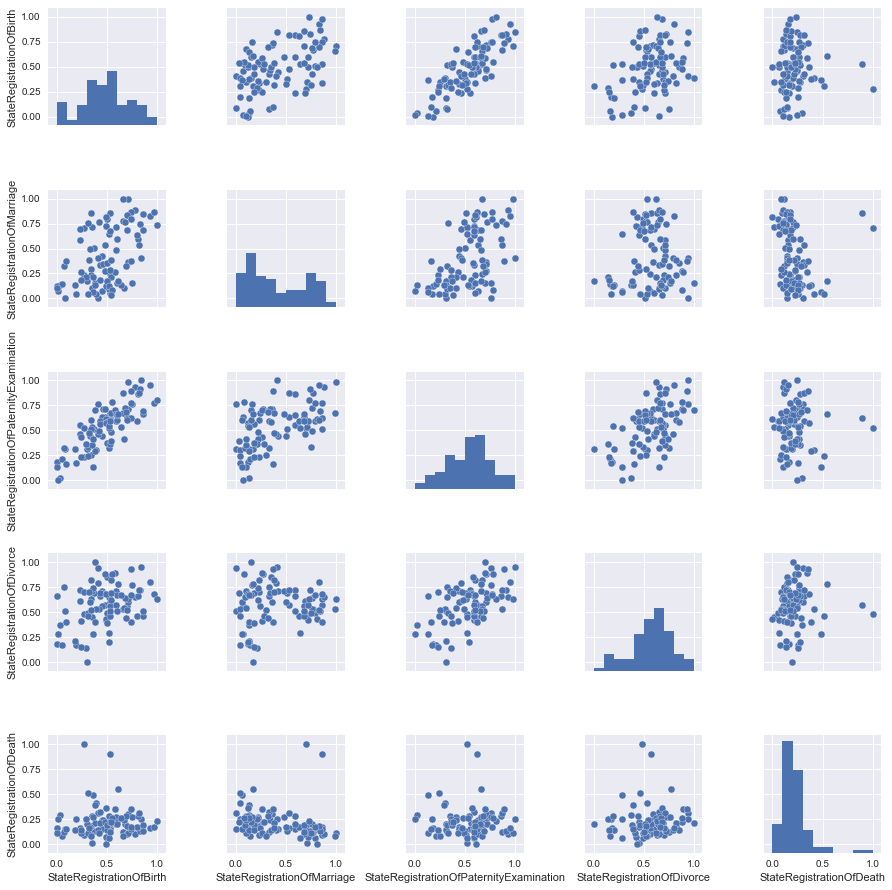
Almost nothing, but for reliability as we take the scaled data.
the
Look at the pictures and see that the best straight line to describe the relationship between two signs StateRegistrationOfBirth and StateRegistrationOfPaternityExamination that is not very surprising (the more often you check "paternity", the more often register children).
Prepare data, select the two column feature and the target feature, then use ready-made libraries divide the data into training and test sample (manipulation at the end of the code was necessary to bring the data to the desired form)
the
It is important to note that despite the apparent ability to bind to the chronology, we for the purpose of demonstration, consider the data as a collection of records without reference to time.
"Feed" our data model and look at the coefficient of our basis, but also to evaluate the accuracy of the fit of the models using R^2 (coefficient of determination).
the
It was not good, on the other hand much better than if we "poked."
View it on the charts, initially, the training data:
the

Now for control:
the
the
To make it more interesting let's choose a different objective function, which is not obviously linearly dependent on the signs.
To match the name of the article, as objective function we choose the registration of marriages.
And all other columns from a set of images paired diagrams make signs.
the
Teach first is simply a linear regression model.
the
Get the result is slightly worse than in the past case (not surprisingly)
To combat overfitting and/or selection of signs, together with the linear regression model typically use the mechanism of regularization, in this article we consider the mechanism of Lasso (L1 – regularization)
The larger the regularization coefficient alpha, the more the model penalizes large values of the signs up to bring some of the coefficients of the regression equation to zero.
the
It should be noted that I do right are the bad things, drove the regularization coefficient under the test data, in reality it wouldn't be, but we purely for demonstration will do.
Look at the output:
In this case, the model with regularization is not much improves the quality, try to add more features.
the
Add the apparently useless symptom of "total registrations", why is that obvious? Now see for yourself.
the
For starters, look at the results without regularization
the
That's crazy! Almost 100% accuracy!
How this characteristic could be called useless?!
Well let's think sensibly, our number of marriages is included in the total amount, so if we have information about other characteristics, then the accuracy is nearing 100%. In practice, this is not particularly useful.
Let's go to our Lasso
First, we choose a small regularization coefficient:
the
Well, nothing much has changed, we're not interested, let's see what happens when it increase.
the
Let's purely out of curiosity, how could explain the percentage registration of marriages only the total number of records.
the
Well not bad, but objectively less than with the other signs.
Let's look at graphics:
the
Let's try to the original dataset, now add another useless sign
State Registration Of Name Change (name change), you can build a model and see what proportion of the data explains this symptom (small believe me).
And we'll find the data and train the model on the old 4x features and useless
the
Won't try regularization, it radically will not change anything, as you can see this symptom only spoils us all.
Let's finally choose a useful feature.
Everyone knows that there is a hot season for weddings (summer and early fall), and there is the quiet season (winter).
the way I was surprised that in may celebrates few weddings.
the
Good improving quality and above all in line with common logic.
the
The last thing we probably need is to look at the linear regression as a tool for predicting the trend. In previous chapters we took the data randomly, that is, in the training set were data from the entire time range. This time we will share data on the past and future and see if we will be able to predict
For convenience we will count the time in months since January 2010, this will write a simple anonymous function, which converts the data eventually will replace the column on the number of months.
Study will be on data up to 2016, and the future for us will be everything that starts in 2016.
the
As can be seen in this breakdown, the accuracy is somewhat reduced and nevertheless, the prediction quality is much better than a finger to the sky.
Verify by looking at graphics.
the
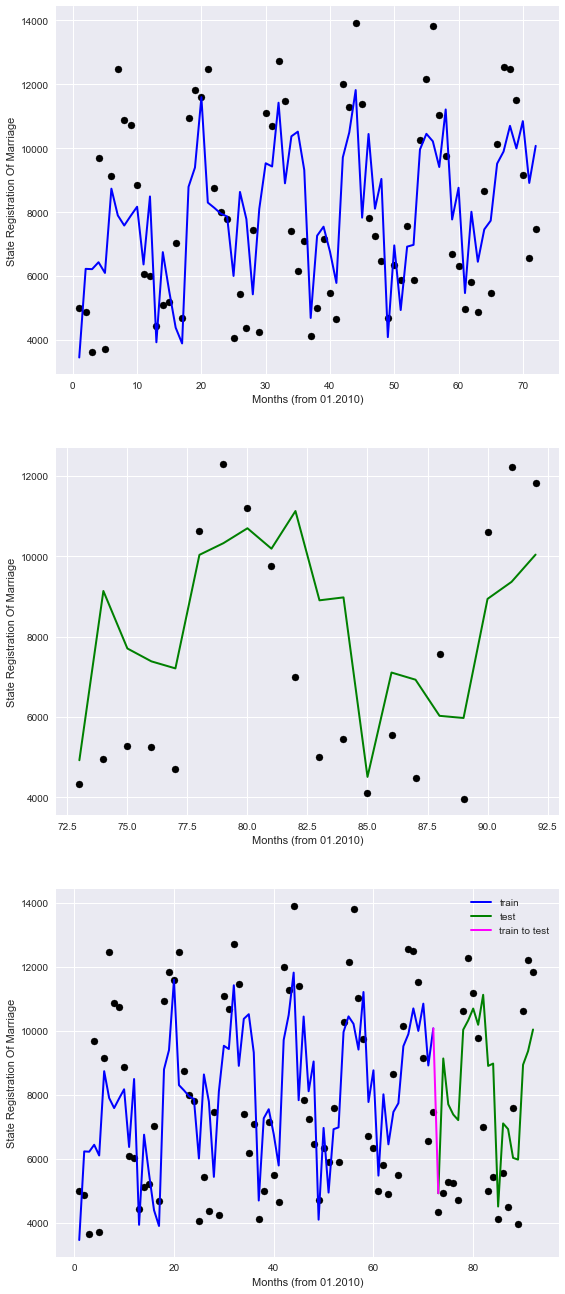
The graphs in blue presented "past," green "future," and purple tie.
So, it is clear that our model perfectly describes the point, but at least takes into account seasonal patterns.
Thus, it is hoped that in the future, according to reports the model will have to somehow Orient, the registration of marriages.
Although trend analysis is where the more advanced tools that are beyond the scope of this article (and in my opinion, elementary skills in Data Science)
the
Well, here we have considered the problem of recovery of a regression, I suggest you look for other relationships on the open data portals of the state structures of the country, maybe you'll find some interesting dependence. As a "challenge" offer, you can dig up anything on the open data portal of the Republic of Belarus opendata.by
At the end of the picture, based on the communication Alexander Lukashenko with reporters answers to inconvenient questions.

the
Colleagues have left helpful comments with recommendations to improve the quality of the prediction.
In short all the proposal was to ensure that in trying to simplify everything, I correctly coded the column "Month" (and indeed it is). To improve this we'll try two ways.
Option 1 — One-hot encoding, where each value of the month is your sign.
To begin, download the original sign without revisions
the
Then apply the one-hot encoding implemented in the library pandas data frame (get_dummies function), delete unneeded columns and start re-training the model and drawing schedules.
the
Get
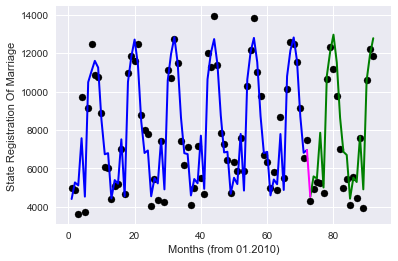
The quality is really grown up!
Option 2 — target encoding, we will encode every month the average value of the objective function for this month on the training sample (thanks to roryorangepants)
the
Will receive:
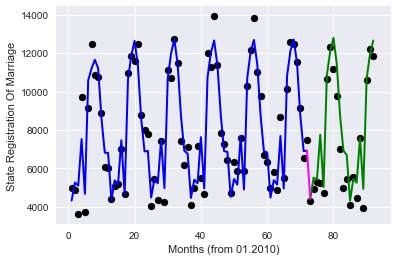
Very similar, in terms of quality of result, with the significantly smaller number of used features.
Well, on this hope all.
Here's good-bye picture with Mr. "Copernicum", I hope it offends no-one and will not cause "holivarov" :)

Article based on information from habrahabr.ru
In recent articles, we looked at a couple of tasks according to the classification in the process of sweat and blood producing their own data, now it's time regression. Because nothing lighting this time at hand was not, I decided to scrape the bottom of the other bottom of the barrel.
I remember in one of the articles I campaigned readers to look towards domestic open data. But since I'm not a young lady of advertising "buttermilk for digestion" or shampoo with horsepower, I couldn't advise anything that is not experienced.
Where to start? Of course with open data of the government of the Russian Federation, there is in fact a whole Ministry there. My acquaintance open data of the government of the Russian Federation, about the same as the illustration to this article. No well not that I wasn't interesting registry Cinema city Novy Urengoy or a list of rolling equipment to the rink in Tula, just for the regression task, they are not very good.
If you dig and think on the website OD the government of the Russian Federation it is possible to find something worthwhile, just not very easily.
Treasury Data I also decided to leave for later.
Perhaps, most of all I liked open data of Moscow government, there I found a couple of potential problems and chose in the end Details about registration of acts of civil status in Moscow by year
What emerged from the implementation of minimum skills in the field of linear regression in summary form to look at GitHuband, of course, looking at kat.
UPD: Added section – "Bonus"
the
Introduction
As usual, in the beginning of the article will talk about the skills necessary for understanding this article.
You will need:
the
-
the
- to Read a tutorial or to run a simple training course on Machine learning the
- to understand a Little bit of Python the
- to Have almost zero knowledge in mathematics
If you are very new in the field of data analysis and machine learning view past articles of the series in order, there is every article written by the "hot pursuit" and you will understand if You should spend time on Data Science.
All of the previously prepared article below.
Other articles of the cycle
1. Learn the basics:
the
2. Practice first skills
the
the
-
the
- "Shop Data big and small!" — (a Brief overview of courses on Data Science from a Cognitive Class) the
- "Now he's counted" or data Science (Data Science from Scratch) the
- "iceberg is Oscar!" or how I tried to learn the basics of DataScience at kaggle the
- ""the little Engine that could!" or "Specialization, Machine learning and data analysis", through the eyes of a beginner in Data Science
2. Practice first skills
the
-
the
- "without a hitch!" or Machine learning (Data science) in C# using Accord.NET Framework the
- "Use the Power of machine learning, Luke!" or automatic classification of lamps according to the KCC
Well, as promised earlier now article in this series will be completed with content.
Contents:
Part I: "to Marry — not the bast wear" — acquisition and primary data analysis.
Part II: "One man is no man" — Regression for 1 basis
Part IV: "all is Not gold that glitters" — Add signs
Part V: "Cut new Abaya, and to the old try!" — Trend forecast
Bonus — Increases the accuracy, at the expense of another approach to months
So, let's get more to the task. It is our goal to dig up some data set sufficient to demonstrate the basic techniques of linear regression and determine that we will predict.
This time will be brief and I will not deviate from the topic examined only the linear regression (you probably know about the existence of other methods)
the
Part I: "to Marry — not a bast Shoe to wear" — acquisition and primary data analysis
Unfortunately open data of the government of Moscow is not so vast and boundless as the budget spent on the improvement of the program "My street", but nonetheless something good to find managed.
Dynamics of registration of civil status acts, we should be fine.
It is nearly a hundred entries, divided by months in which there are data on the number of weddings, births, establishment of parenthood, deaths, changes of name, etc.
To solve the problem of regression is fine.
All the code hosted on GitHub
Well then we dissect it right now.
To begin importing the library:
the
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn import linear_model
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
Then load the data. The Pandas library allows you to download files from a remote server that in General is just great, provided of course that the portal will not change the algorithm of redirection pages.
(I hope that the download link in the code, will not be covered if it stops working please write in "personal", so I can update)
the
#download
df = pd.read_csv('https://op.mos.ru/EHDWSREST/catalog/export/get?id=230308', compression='zip', header=0, encoding='cp1251', sep=';', quotechar='"')
#look at the data
df.head(12)
Look at the data:
| ID | global_id | Year | Month | StateRegistrationOfBirth | StateRegistrationOfDeath | StateRegistrationOfMarriage | StateRegistrationOfDivorce | StateRegistrationOfPaternityExamination | StateRegistrationOfAdoption | StateRegistrationOfNameChange | TotalNumber |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 37591658 | 2010 | January | 9206 | 10430 | 4997 | 3302 | 1241 | 95 | 491 | 29762 |
| 2 | 37591659 | 2010 | February | 9060 | 9573 | 4873 | 2937 | 1326 | 97 | 639 | 28505 |
| 3 | 37591660 | 2010 | March | 10934 | 10528 | 3642 | 4361 | 1644 | 147 | 717 | 31973 |
| 4 | 37591661 | 2010 | APR | 10140 | 9501 | 9698 | 3943 | 1530 | 128 | 642 | 35572 |
| 5 | 37591662 | 2010 | may | 9457 | 9482 | 3726 | 3554 | 1397 | 96 | 492 | 28204 |
| 6 | 62353812 | 2010 | Jun | 11253 indoor | 9529 | 9148 | 3666 | 1570 | 130 | 556 | 35852 |
| 7 | 62353813 | 2010 | Jul | 11477 | 14340 | 12473 | 3675 | 1568 | 123 | 564 | 44220 |
| 8 | 62353814 | 2010 | August | 10302 | 15016 | 10882 | 3496 | 1512 | 134 | 578 | 41920 |
| 9 | 62353816 | 2010 | Sep | 10140 | 9573 | 10736 | 3738 | 1480 | 101 | 686 | 36454 |
| 10 | 62353817 | 2010 | Oct | 10776 | 9350 | 8862 | 3899 | 1504 | 89 | 687 | 35167 |
| 11 | 62353818 | 2010 | Nov | 10293 | 9091 | 6080 | 3923 | 1355 | 97 | 568 | 31407 |
| 12 | 62353819 | 2010 | Dec | 10600 | 9664 | 6023 | 4145 | 1556 | 124 | 681 | 32793 |
If we want to use information about months, they must be translated into an understandable model format, scikit-learn has its own methods, but for reliability we will make (for not a lot of work) and at the same time remove a couple of useless in our case, the columns ID and junk.
note: in this case, the graph of the Month, I think it would be more appropriate to use one-hot encoding, but because in this case us quality predictions are not much interested, I will leave it as is.
UPD: broke down and added a corrected version in the Bonus
the
#code months
d={'January':1, 'February':2, 'March':3, 'APR':4, 'may':5, 'June':6, 'July':7,
'August':8, 'Sep':9, 'Oct':10, 'Nov':11, 'Dec':12}
df.Month=df.Month.map(d)
#delete some unuseful columns
df.drop(['ID','global_id','Unnamed: 12'],axis=1,inplace=True)
#look at the data
df.head(12)
Because I'm not sure that table view all opens normally look at the data with the help of pictures.
Build a pair of charts, from which it will be clear which columns of our table, linearly independent from each other. However, once all of the data we will not consider, so you have something to add, so first get some data.
A fairly simple way to highlight (delete) a subset of columns in a pandas Dataframe is just to make selection according to the desired columns:
the
columns_to_show = ['StateRegistrationOfBirth', 'StateRegistrationOfMarriage',
'StateRegistrationOfPaternityExamination', 'StateRegistrationOfDivorce','StateRegistrationOfDeath']
data=df[columns_to_show]
Well now you can and schedule to build.
the
grid = sns.pairplot(data)
A good practice is to feature scaling, not to compare horses with the weight of the stacks of hay and the average atmospheric pressure during the month.
In our case, all data are presented in the same units (number of registered acts), but let's see what will change the scaling.
the
# change scale of features
scaler = MinMaxScaler()
df2=pd.DataFrame(scaler.fit_transform(df))
df2.columns=df.columns
data2=df2[columns_to_show]
grid2 = sns.pairplot(data2)
Almost nothing, but for reliability as we take the scaled data.
the
Part II: "One man is no man" — Regression for 1 basis
Look at the pictures and see that the best straight line to describe the relationship between two signs StateRegistrationOfBirth and StateRegistrationOfPaternityExamination that is not very surprising (the more often you check "paternity", the more often register children).
Prepare data, select the two column feature and the target feature, then use ready-made libraries divide the data into training and test sample (manipulation at the end of the code was necessary to bring the data to the desired form)
the
X = data2['StateRegistrationOfBirth'].values
y = data2['StateRegistrationOfPaternityExamination'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
X_train=np.reshape(X_train,[X_train.shape[0],1])
y_train=np.reshape(y_train,[y_train.shape[0],1])
X_test=np.reshape(X_test,[X_test.shape[0],1])
y_test=np.reshape(y_test,[y_test.shape[0],1])
It is important to note that despite the apparent ability to bind to the chronology, we for the purpose of demonstration, consider the data as a collection of records without reference to time.
"Feed" our data model and look at the coefficient of our basis, but also to evaluate the accuracy of the fit of the models using R^2 (coefficient of determination).
the
#teach, model and get predictions
lr = linear_model.LinearRegression()
lr.fit(X_train, y_train)
print('Coefficients:', lr.coef_)
print('Score:', lr.score(X_test,y_test))
It was not good, on the other hand much better than if we "poked."
Coefficients: [[ 0.78600258]]
Score: 0.611493944197
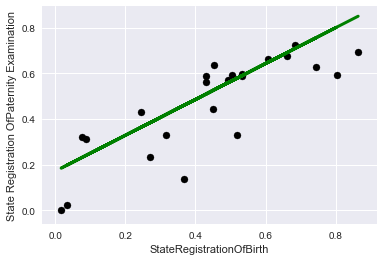
View it on the charts, initially, the training data:
the
plt.scatter(X_train, y_train, color='black')
plt.plot(X_train, lr.predict(X_train), color='blue',
linewidth=3)
plt.xlabel('StateRegistrationOfBirth')
plt.ylabel('State Registration Examination OfPaternity')
plt.title="Regression on train data"
Now for control:
the
plt.scatter(X_test, y_test, color='black')
plt.plot(X_test, lr.predict(X_test), color='green',
linewidth=3)
plt.xlabel('StateRegistrationOfBirth')
plt.ylabel('State Registration Examination OfPaternity')
plt.title="Regression on test data"
the
Part III: "One head is good, a lot better" — Regression on several grounds regularization
To make it more interesting let's choose a different objective function, which is not obviously linearly dependent on the signs.
To match the name of the article, as objective function we choose the registration of marriages.
And all other columns from a set of images paired diagrams make signs.
the
#get main data
columns_to_show2=columns_to_show.copy()
columns_to_show2.remove("StateRegistrationOfMarriage")
#get data for a model
X = data2[columns_to_show2].values
y = data2['StateRegistrationOfMarriage'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
y_train=np.reshape(y_train,[y_train.shape[0],1])
y_test=np.reshape(y_test,[y_test.shape[0],1])
Teach first is simply a linear regression model.
the
lr = linear_model.LinearRegression()
lr.fit(X_train, y_train)
print('Coefficients:', lr.coef_)
print('Score:', lr.score(X_test,y_test))
Get the result is slightly worse than in the past case (not surprisingly)
Coefficients: [[-0.03475475 0.97143632 -0.44298685 -0.18245718]]
Score: 0.38137432065
To combat overfitting and/or selection of signs, together with the linear regression model typically use the mechanism of regularization, in this article we consider the mechanism of Lasso (L1 – regularization)
The larger the regularization coefficient alpha, the more the model penalizes large values of the signs up to bring some of the coefficients of the regression equation to zero.
the
#let's look at the different alpha parameter:
#large
Rid=linear_model.Lasso (alpha = 0.01)
Rid.fit(X_train, y_train)
print(' Appha:', Rid.alpha)
print(' Coefficients:', Rid.coef_)
print(' Score:', Rid.score(X_test,y_test))
#Small
Rid=linear_model.Lasso (alpha = 0.000000001)
Rid.fit(X_train, y_train)
print('\n Appha:', Rid.alpha)
print(' Coefficients:', Rid.coef_)
print(' Score:', Rid.score(X_test,y_test))
#Optimal (for these test data)
Rid=linear_model.Lasso (alpha = 0.00025)
Rid.fit(X_train, y_train)
print('\n Appha:', Rid.alpha)
print(' Coefficients:', Rid.coef_)
print(' Score:', Rid.score(X_test,y_test))
It should be noted that I do right are the bad things, drove the regularization coefficient under the test data, in reality it wouldn't be, but we purely for demonstration will do.
Look at the output:
Appha: 0.01
Coefficients: [ 0. 0.46642996 -0. -0. ]
Score: 0.222071102783
Appha: 1e-09
Coefficients: [-0.03475462 0.97143616 -0.44298679 -0.18245715]
Score: 0.38137433837
Appha: 0.00025
Coefficients: [-0.00387233 0.92989507 -0.42590052 -0.17411615]
Score: 0.385551648602
In this case, the model with regularization is not much improves the quality, try to add more features.
the
Part IV: "all is Not gold that glitters" — the characteristics that are Added
Add the apparently useless symptom of "total registrations", why is that obvious? Now see for yourself.
the
columns_to_show3=columns_to_show2.copy()
columns_to_show3.append("TotalNumber")
columns_to_show3
X = df2[columns_to_show3].values
# y hasn't changed
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
y_train=np.reshape(y_train,[y_train.shape[0],1])
y_test=np.reshape(y_test,[y_test.shape[0],1])
For starters, look at the results without regularization
the
lr = linear_model.LinearRegression()
lr.fit(X_train, y_train)
print('Coefficients:', lr.coef_)
print('Score:', lr.score(X_test,y_test))
Coefficients: [[-0.45286477 -0.08625204 -0.19375198 -0.63079401 1.57467774]]
Score: 0.999173764473
That's crazy! Almost 100% accuracy!
How this characteristic could be called useless?!
Well let's think sensibly, our number of marriages is included in the total amount, so if we have information about other characteristics, then the accuracy is nearing 100%. In practice, this is not particularly useful.
Let's go to our Lasso
First, we choose a small regularization coefficient:
the
#Optimal (for these test data)
Rid=linear_model.Lasso (alpha = 0.00015)
Rid.fit(X_train, y_train)
print('\n Appha:', Rid.alpha)
print(' Coefficients:', Rid.coef_)
print(' Score:', Rid.score(X_test,y_test))
Appha: 0.00015
Coefficients: [-0.44718703 -0.07491507 -0.1944702 -0.62034146 1.55890505]
Score: 0.999266251287
Well, nothing much has changed, we're not interested, let's see what happens when it increase.
the
#large
Rid=linear_model.Lasso (alpha = 0.01)
Rid.fit(X_train, y_train)
print('\n Appha:', Rid.alpha)
print(' Coefficients:', Rid.coef_)
print(' Score:', Rid.score(X_test,y_test))
Appha: 0.01
Coefficients: [-0. -0. -0. -0.05177979 0.87991931]
Score: 0.802210158982
Let's purely out of curiosity, how could explain the percentage registration of marriages only the total number of records.
the
X_train=np.reshape(X_train[:,4],[X_train.shape[0],1])
X_test=np.reshape(X_test[:,4],[X_test.shape[0],1])
lr = linear_model.LinearRegression()
lr.fit(X_train, y_train)
print('Coefficients:', lr.coef_)
print('Score:', lr.score(X_train,y_train))
Coefficients: [ 1.0571131]
Score: 0.788270672692
Well not bad, but objectively less than with the other signs.
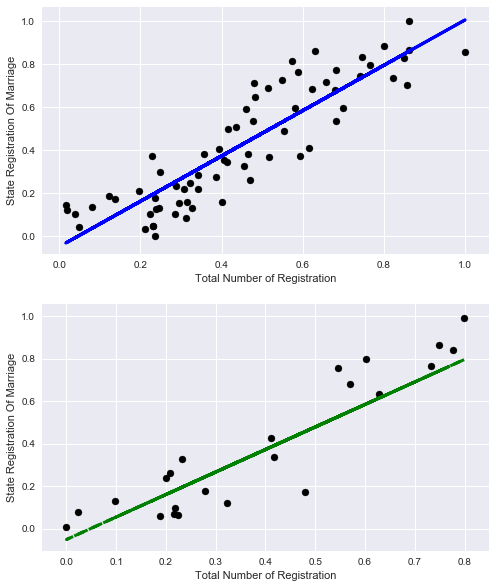
Let's look at graphics:
the
# plot train data for
plt.figure(figsize=(8,10))
plt.subplot(211)
plt.scatter(X_train, y_train, color='black')
plt.plot(X_train, lr.predict(X_train), color='blue',
linewidth=3)
plt.xlabel('Total Number of Registration')
plt.ylabel('State Registration Of Marriage')
plt.title="Regression on train data"
# plot for test data
plt.subplot(212)
plt.scatter(X_test, y_test, color='black')
plt.plot(X_test, lr.predict(X_test), '--', color='green',
linewidth=3)
plt.xlabel('Total Number of Registration')
plt.ylabel('State Registration Of Marriage')
plt.title="Regression on test data"Let's try to the original dataset, now add another useless sign
State Registration Of Name Change (name change), you can build a model and see what proportion of the data explains this symptom (small believe me).
And we'll find the data and train the model on the old 4x features and useless
the
columns_to_show4=columns_to_show2.copy()
columns_to_show4.append("StateRegistrationOfNameChange")
X = df2[columns_to_show4].values
# y hasn't changed
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
y_train=np.reshape(y_train,[y_train.shape[0],1])
y_test=np.reshape(y_test,[y_test.shape[0],1])
lr = linear_model.LinearRegression()
lr.fit(X_train, y_train)
print('Coefficients:', lr.coef_)
print('Score:', lr.score(X_test,y_test))
Coefficients: [[ 0.06583714 1.1080889 -0.35025999 -0.24473705 -0.4513887 ]]
Score: 0.285094398157
Won't try regularization, it radically will not change anything, as you can see this symptom only spoils us all.
Let's finally choose a useful feature.
Everyone knows that there is a hot season for weddings (summer and early fall), and there is the quiet season (winter).
the way I was surprised that in may celebrates few weddings.
the
#get data
columns_to_show5=columns_to_show2.copy()
columns_to_show5.append("Month")
#get data for model
X = df2[columns_to_show5].values
# y hasn't changed
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
y_train=np.reshape(y_train,[y_train.shape[0],1])
y_test=np.reshape(y_test,[y_test.shape[0],1])
#teach, model and get predictions
lr = linear_model.LinearRegression()
lr.fit(X_train, y_train)
print('Coefficients:', lr.coef_)
print('Score:', lr.score(X_test,y_test))
Coefficients: [[-0.10613428 0.91315175 -0.55413198 -0.13253367 0.28536285]]
Score: 0.472057997208
Good improving quality and above all in line with common logic.
the
Part V: "Cut new Abaya, and to the old try!" — Trend forecast
The last thing we probably need is to look at the linear regression as a tool for predicting the trend. In previous chapters we took the data randomly, that is, in the training set were data from the entire time range. This time we will share data on the past and future and see if we will be able to predict
For convenience we will count the time in months since January 2010, this will write a simple anonymous function, which converts the data eventually will replace the column on the number of months.
Study will be on data up to 2016, and the future for us will be everything that starts in 2016.
the
#get data
df3=df.copy()
#get new column
df3.Year=df.Year.map(lambda x: (x-2010)*12)+df.Month
df3.rename(columns={'Year': 'Month'}, inplace=True)
#get data for model
X=df3[columns_to_show5].values
y=df3['StateRegistrationOfMarriage'].values
train=[df3.Months<=72]
test=[df3.Months>72]
X_train=X[train]
y_train=y[train]
X_test=X[test]
y_test=y[test]
y_train=np.reshape(y_train,[y_train.shape[0],1])
y_test=np.reshape(y_test,[y_test.shape[0],1])
#teach, model and get predictions
lr = linear_model.LinearRegression()
lr.fit(X_train, y_train)
print('Coefficients:', lr.coef_[0])
print('Score:', lr.score(X_test,y_test))
Coefficients: [ 2.60708376 e-01 1.30751121 e+01 -3.31447168 e+00 -2.34368684 e-01
2.88096512 e+02].
Score: 0.383195050367
As can be seen in this breakdown, the accuracy is somewhat reduced and nevertheless, the prediction quality is much better than a finger to the sky.
Verify by looking at graphics.
the
plt.figure(figsize=(of 9.23))
# plot train data for
plt.subplot(311)
plt.scatter(df3.Months.values[train], y_train, color='black')
plt.plot(df3.Months.values[train], lr.predict(X_train), color='blue', linewidth=2)
plt.xlabel('Months (from 01.2010)')
plt.title="Regression on train data"
# plot for test data
plt.subplot(312)
plt.scatter(df3.Months.values[test], y_test, color='black')
plt.plot(df3.Months.values[test], lr.predict(X_test), color='green', linewidth=2)
plt.xlabel('Months (from 01.2010)')
plt.ylabel('State Registration Of Marriage')
plt.title="Regression (prediction) on test data"
# plot for all data
plt.subplot(313)
plt.scatter(df3.Months.values[train], y_train, color='black')
plt.plot(df3.Months.values[train], lr.predict(X_train), color='blue', label='train', linewidth=2)
plt.scatter(df3.Months.values[test], y_test, color='black')
plt.plot(df3.Months.values[test], lr.predict(X_test), color='green', label='test', linewidth=2)
plt.title="Regression (prediction) on all data"
plt.xlabel('Months (from 01.2010)')
plt.ylabel('State Registration Of Marriage')
#plot line for link train to test
plt.plot([72,73], lr.predict([X_train[-1],X_test[0]]) , color='magenta',linewidth=2, label='train to test')
plt.legend()
The graphs in blue presented "past," green "future," and purple tie.
So, it is clear that our model perfectly describes the point, but at least takes into account seasonal patterns.
Thus, it is hoped that in the future, according to reports the model will have to somehow Orient, the registration of marriages.
Although trend analysis is where the more advanced tools that are beyond the scope of this article (and in my opinion, elementary skills in Data Science)
the
Conclusion
Well, here we have considered the problem of recovery of a regression, I suggest you look for other relationships on the open data portals of the state structures of the country, maybe you'll find some interesting dependence. As a "challenge" offer, you can dig up anything on the open data portal of the Republic of Belarus opendata.by
At the end of the picture, based on the communication Alexander Lukashenko with reporters answers to inconvenient questions.
the
Bonus — Increases the accuracy, at the expense of another approach to months
Colleagues have left helpful comments with recommendations to improve the quality of the prediction.
In short all the proposal was to ensure that in trying to simplify everything, I correctly coded the column "Month" (and indeed it is). To improve this we'll try two ways.
Option 1 — One-hot encoding, where each value of the month is your sign.
To begin, download the original sign without revisions
the
df_base = pd.read_csv('https://op.mos.ru/EHDWSREST/catalog/export/get?id=230308', compression='zip', header=0, encoding='cp1251', sep=';', quotechar='"')
Then apply the one-hot encoding implemented in the library pandas data frame (get_dummies function), delete unneeded columns and start re-training the model and drawing schedules.
the
#get data for model
df4=df_base.copy()
df4.drop(['Year','StateRegistrationOfMarriage','ID','global_id','Unnamed: 12','TotalNumber','StateRegistrationOfNameChange','StateRegistrationOfAdoption'],axis=1,inplace=True)
df4=pd.get_dummies(df4,prefix=['Month'])
X=df4.values
X_train=X[train]
X_test=X[test]
#teach, model and get predictions
lr = linear_model.LinearRegression()
lr.fit(X_train, y_train)
print('Coefficients:', lr.coef_[0])
print('Score:', lr.score(X_test,y_test))
# plot for all data
plt.scatter(df3.Months.values[train], y_train, color='black')
plt.plot(df3.Months.values[train], lr.predict(X_train), color='blue', label='train', linewidth=2)
plt.scatter(df3.Months.values[test], y_test, color='black')
plt.plot(df3.Months.values[test], lr.predict(X_test), color='green', label='test', linewidth=2)
plt.title="Regression (prediction) on all data"
plt.xlabel('Months (from 01.2010)')
plt.ylabel('State Registration Of Marriage')
#plot line for link train to test
plt.plot([72,73], lr.predict([X_train[-1],X_test[0]]) , color='magenta',linewidth=2, label='train to test')
Get
Coefficients: [ 2.18633008 e-01 -1.41397731 e-01 4.56991414 e-02 -5.17558633 e-01
4.48131002 e+03 -2.94754108 e+02 -1.14429758 e+03 3.61201946 e+03
2.41208054 e+03 -3.23415050 e+03 -2.73587261 e+03 -1.31020899 e+03
4.84757208 e+02 3.37280689 e+03 -2.40539320 e+03 -3.23829714 e+03].
Score: 0.869208071831
The quality is really grown up!
Option 2 — target encoding, we will encode every month the average value of the objective function for this month on the training sample (thanks to roryorangepants)
the
#get data for pandas data frame
df5=df_base.copy()
d=dict()
#get we obtain the mean value of Registration Of Marriages by months on the training data
for mon in df5.Month.unique():
d[mon]=df5.StateRegistrationOfMarriage[df5.Month.values[train]==mon].mean()
#d+={}
df5['MeanMarriagePerMonth']=df5.Month.map(d)
df5.drop(['Month','Year','StateRegistrationOfMarriage','ID','global_id','Unnamed: 12','TotalNumber',
#get data for model
X=df5.values
X_train=X[train]
X_test=X[test]
#teach, model and get predictions
lr = linear_model.LinearRegression()
lr.fit(X_train, y_train)
print('Coefficients:', lr.coef_[0])
print('Score:', lr.score(X_test,y_test))
# plot for all data
plt.scatter(df3.Months.values[train], y_train, color='black')
plt.plot(df3.Months.values[train], lr.predict(X_train), color='blue', label='train', linewidth=2)
plt.scatter(df3.Months.values[test], y_test, color='black')
plt.plot(df3.Months.values[test], lr.predict(X_test), color='green', label='test', linewidth=2)
plt.title="Regression (prediction) on all data"
plt.xlabel('Months (from 01.2010)')
plt.ylabel('State Registration Of Marriage')
#plot line for link train to test
plt.plot([72,73], lr.predict([X_train[-1],X_test[0]]) , color='magenta',linewidth=2, label='train to test')-
Will receive:
Coefficients: [ 0.16556761 -0.12746446 -0.03652408 -0.21649349 0.96971467]
Score: 0.875882918435
Very similar, in terms of quality of result, with the significantly smaller number of used features.
Well, on this hope all.
Here's good-bye picture with Mr. "Copernicum", I hope it offends no-one and will not cause "holivarov" :)


Комментарии
Отправить комментарий